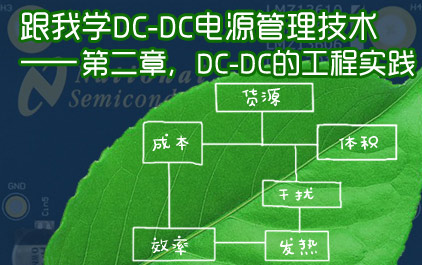
技术
关注204人关注
我要报错
世界知识产权组织在1977年版的《供发展中国家使用的许可证贸易手册》中,给技术下的定义:“技术是制造一种产品的系统知识,所采用的一种工艺或提供的一项服务,不论这种知识是否反映在一项发明、一项外形设计、一项实用新型或者一种植物新品种,或者反映在技术情报或技能中,或者反映在专家为设计、安装、开办或维修一个工厂或为管理一个工商业企业或其活动而提供的服务或协助等方面。”这是至今为止国际上给技术所下的最为全面和完整的定义。实际上知识产权组织把世界上所有能带来经济效益的科学知识都定义为技术。
热门帖子
相关项目
- 预算:¥50000
基于RK3506/RK3568硬件平台、双系统架构的EtherCAT主
预算:¥50000- 预算:¥20000
- 预算:¥200000
- 预算:¥5000
- 预算:¥50000
- 预算:¥500000
- 预算:¥50000
- 预算:¥200000
- 预算:¥200000
杨文卿
baplmqj
林翊宸爸爸
孙玉其
yang316323692
xiaofei558008
racoy
af10000
heilongqq
masmin
xudaofu
zchong
情歌被打败
sw小位
yangbingru
神经男
paranoea2018
stm32jy
季冬
ddllxxrr