
Q 版老黄带着硬核技术再登场,有点可爱,很有东西
时间:2021-11-11 14:23:12
[导读]编译|禾木木出品| AI科技大本营(ID:rgznai100)看到下面这个老黄是不是觉得很Q~11月9日,GTC大会再次来了,英伟达创始人兼CEO黄仁勋再次从自己虚拟厨房走出来。本次GTC大会都有哪些亮点呢?Q版黄仁勋 英伟达展示过如何使用Omniverse来模拟仓库、工厂、物理...
 编译 | 禾木木出品 | AI科技大本营(ID:rgznai100)看到下面这个老黄是不是觉得很Q~
编译 | 禾木木出品 | AI科技大本营(ID:rgznai100)看到下面这个老黄是不是觉得很Q~ 11月9日,GTC 大会再次来了,英伟达创始人兼CEO黄仁勋再次从自己虚拟厨房走出来。本次 GTC 大会都有哪些亮点呢?
11月9日,GTC 大会再次来了,英伟达创始人兼CEO黄仁勋再次从自己虚拟厨房走出来。本次 GTC 大会都有哪些亮点呢?

Q 版黄仁勋
 英伟达展示过如何使用 Omniverse 来模拟仓库、工厂、物理与生物系统、5G 通信、机器人、自动驾驶汽车,现在最新的技术可以直接生成全功能的虚拟形象了。这个 Q 版老黄叫 Toy-Me,可以和人进行自然语言交流。它使用了目前规模最大的预训练自然语言处理模型 Megatron 530B,通过自己的声音、形象和讲话姿势,整个人也带光追特效。one more thing !这一切都是实时生成的。黄仁勋表示,“你会看到这个虚拟形象是基于目前训练的最大语言模型的语言处理打造,包括声音也是用我自己的语音进行合成,还可以看到实时基于光线追踪的精美图像。”黄仁勋演示3个人分别让虚拟形象回答关于气候变化、天文学以及生物蛋白质等问题,都可以对答如流。可谓是上知天文,下知地理!
英伟达展示过如何使用 Omniverse 来模拟仓库、工厂、物理与生物系统、5G 通信、机器人、自动驾驶汽车,现在最新的技术可以直接生成全功能的虚拟形象了。这个 Q 版老黄叫 Toy-Me,可以和人进行自然语言交流。它使用了目前规模最大的预训练自然语言处理模型 Megatron 530B,通过自己的声音、形象和讲话姿势,整个人也带光追特效。one more thing !这一切都是实时生成的。黄仁勋表示,“你会看到这个虚拟形象是基于目前训练的最大语言模型的语言处理打造,包括声音也是用我自己的语音进行合成,还可以看到实时基于光线追踪的精美图像。”黄仁勋演示3个人分别让虚拟形象回答关于气候变化、天文学以及生物蛋白质等问题,都可以对答如流。可谓是上知天文,下知地理!

Omniverse Avatar 发布
在此次大会上,英伟达宣布推出 NVIDIA Omniverse Avatar,这是一个用于生成交互式 AI 虚拟形象的技术平台。
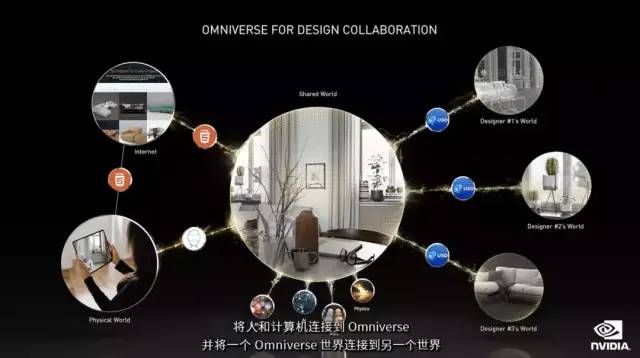 Omniverse Avatar 是一款基于语言、计算机视觉、自然语言理解、推荐引擎和模拟技术生成的交互式 AI 化身。它具有光线追踪 3D 图形的交互式角色,可以看到、说话、就广泛的主题进行交谈,并理解对话的意图。
Omniverse Avatar 是一款基于语言、计算机视觉、自然语言理解、推荐引擎和模拟技术生成的交互式 AI 化身。它具有光线追踪 3D 图形的交互式角色,可以看到、说话、就广泛的主题进行交谈,并理解对话的意图。 Omniverse Avatar 为创建人工智能助手打开了大门,这些助手几乎可以为任何行业轻松定制。这些可以帮助处理数十亿的日常客户服务互动,像是餐厅订单、银行交易、个人约会和预订等等,从而带来更多商机并提高客户满意度。
Omniverse Avatar 为创建人工智能助手打开了大门,这些助手几乎可以为任何行业轻松定制。这些可以帮助处理数十亿的日常客户服务互动,像是餐厅订单、银行交易、个人约会和预订等等,从而带来更多商机并提高客户满意度。 这个小机器人可以通过语音识别、眼神追踪来推断顾客的意图,并能在2秒左右作出反应,回答顾客提出的问题或要求。“智能虚拟助手的曙光已经到来,”英伟达创始人兼首席执行官黄仁勋表示。“Omniverse Avatar 结合了英伟达的基础图形、模拟和 AI 技术,创造了一些有史以来最复杂的实时应用程序。协作机器人和虚拟助手的用例令人难以置信且影响深远。”
这个小机器人可以通过语音识别、眼神追踪来推断顾客的意图,并能在2秒左右作出反应,回答顾客提出的问题或要求。“智能虚拟助手的曙光已经到来,”英伟达创始人兼首席执行官黄仁勋表示。“Omniverse Avatar 结合了英伟达的基础图形、模拟和 AI 技术,创造了一些有史以来最复杂的实时应用程序。协作机器人和虚拟助手的用例令人难以置信且影响深远。”

Omniverse Avatar 技术应用
Omniverse Avatar 的语音识别是基于英伟达 Riva,这是一种软件开发工具包,可识别多种语言的语音。Riva 还用于使用文本到语音功能生成类似人类的语音响应。
 Avatar 的自然语言理解是基于 Megatron 530B 大型语言模型,能够识别、理解和生成人类语言。Megatron 530B 是一个预训练模型,它可以在很少或根本没有训练的情况下完成句子,例如:回答大量主题领域的问题,完形填空、阅读理解、常识推理,自然语言推理、翻译成其他语言等,除了这些训练完,还可以处理许多未经专门训练的领域。Avatar 的推荐引擎由 NVIDIA Merlin 提供,该框架允许企业构建能够处理大量数据的深度学习推荐系统,以提出更明智建议。 Avatar 的感知能力由NVIDIA Metropolis启用,这是一种用于视频分析的计算机视觉框架。头像动画由 NVIDIA Video2Face 和Audio2Face、2D 和 3D 人工智能驱动的面部动画和渲染技术提供支持。Omniverse Avatar 将这些技术被组合成一个应用程序,并使用 NVIDIA 统一计算框架进行实时处理。在 Keynote 中,英伟达还展示了 Omniverse 的一系列新功能,包括 Showroom,负责展示图形、物理、材质和 AI。Farm一个系统层,用于协调跨多系统,工作站、服务器、裸机或虚拟化的批处理作业。Omniverse AR 可以将图形串流到手机和 AR 眼镜上。Omniverse VR 是首款全帧率交互式光线追踪 VR。
Avatar 的自然语言理解是基于 Megatron 530B 大型语言模型,能够识别、理解和生成人类语言。Megatron 530B 是一个预训练模型,它可以在很少或根本没有训练的情况下完成句子,例如:回答大量主题领域的问题,完形填空、阅读理解、常识推理,自然语言推理、翻译成其他语言等,除了这些训练完,还可以处理许多未经专门训练的领域。Avatar 的推荐引擎由 NVIDIA Merlin 提供,该框架允许企业构建能够处理大量数据的深度学习推荐系统,以提出更明智建议。 Avatar 的感知能力由NVIDIA Metropolis启用,这是一种用于视频分析的计算机视觉框架。头像动画由 NVIDIA Video2Face 和Audio2Face、2D 和 3D 人工智能驱动的面部动画和渲染技术提供支持。Omniverse Avatar 将这些技术被组合成一个应用程序,并使用 NVIDIA 统一计算框架进行实时处理。在 Keynote 中,英伟达还展示了 Omniverse 的一系列新功能,包括 Showroom,负责展示图形、物理、材质和 AI。Farm一个系统层,用于协调跨多系统,工作站、服务器、裸机或虚拟化的批处理作业。Omniverse AR 可以将图形串流到手机和 AR 眼镜上。Omniverse VR 是首款全帧率交互式光线追踪 VR。
NeMo Megatron 框架
在 GTC 大会上,NVIDIA 推出了为训练具有数万亿参数的语言模型而优化的 NVIDIA NeMo Megatron 框架、为新领域和语言进行训练的可定制大型语言模型(LLM)Megatron 530B 以及具有多 GPU、多节点分布式推理功能的 NVIDIA Triton 推理服务器。这些工具与 NVIDIA DGX 系统相结合,提供了一个可部署到实际生产环境的企业级解决方案,以简化大型语言模型的开发和部署。“训练大型语言模型需要极大的勇气:耗资上亿美元的系统、持续数月在数 PB 数据上训练万亿参数模型,离不开强大的信念、深厚的专业知识和优化的堆栈”黄仁勋表示。因此,他们创建了一个专门训练拥有数万亿参数的语音、语言模型的框架——NeMo Megatron。NeMo Megatron 是在 Megatron 的基础上发展起来的开源项目,由 NVIDIA 研究人员主导,研究大型 Transformer 语言模型的高效训练。该框架已经经过优化,可水平扩展至大规模系统并保持很高的计算效率。该框架使用数据处理库自动处理 LLM 复杂训练,可以获取、管理、组织和清理数据。它使用先进的数据、张量和管道并行化技术,使大型语言模型的训练能够高效地分布在数千个GPU上。为了解决大模型推理问题,NVIDIA 创建了 Triton 推理服务器。黄仁勋表示,Triton 是世界上第一个分布式推理服务器,可以在多个 GPU 和多个节点之间进行分布式推理。有了 Triton,GPT-3 可以轻松运行在 8-GPU 服务器上;Megatron 530B 可以分布部署在两个 DGX 系统中,推理时间从 1 分钟缩短至半秒。
人工智能驱动软件技术
英伟达还宣布了2项新人工智能驱动软件技术——Nvidia Drive Concierge 和 Drive Chauffeur。机器人能够在和驾驶员沟通后,调整车辆的行驶模式。最有趣的是 Nvidia Drive Concierge 这个AI助理与 Nvidia Drive AV 自动驾驶技术的集成,可以根据需求提供泊车。当你说寻找停车位时,可以为你自动停车。本次GTC大会给大家展示了很多重要的点,你怎么看呢?参考链接:https://nvidianews.nvidia.com/news/nvidia-announces-platform-for-creating-ai-avatarshttps://www.nvidia.cn/gtc-global/keynote/





